简介
HDFS(Hadoop Distributed File System)是Apache Hadoop生态系统的一部分,是一种分布式文件系统,旨在处理大规模数据集的存储和处理。
以下是HDFS的一些关键特点和功能:
- 分布式存储:HDFS将数据分布式存储在多个物理节点上,以实现高容量和高可靠性。数据被划分为多个数据块(block),并在集群中的多个节点上进行复制存储,以提供容错能力和数据冗余。
- 扩展性:HDFS可以扩展到大规模的数据集和节点数。它可以运行在大型集群上,通过添加更多的节点来增加存储容量和数据处理能力。
- 容错性:HDFS通过数据的冗余复制来提供容错能力。每个数据块会在集群中的多个节点上进行复制存储,以防止节点故障导致数据丢失。
- 高吞吐量:HDFS优化了数据访问的方式,通过顺序读写和数据本地性原则,实现高吞吐量的数据访问。这使得HDFS适用于大数据处理任务,如批处理、数据分析和大规模并行计算。
- 数据局部性:HDFS将计算任务移动到存储数据的节点附近,以减少数据传输的网络开销,提高性能。这种数据局部性原则有助于优化数据处理的效率。
- 写一次、多次读取:HDFS适用于一次写入多次读取的应用场景。一旦数据被写入HDFS,可以多次读取和处理,以满足不同的分析和计算需求。
HDFS是Hadoop生态系统中的核心组件之一,被广泛应用于大数据处理和分析任务。它提供了可靠的分布式存储解决方案,适合用于处理大规模数据集和构建数据湖(Data Lake)等数据管理和处理系统。
1.Linux系统安装
1.环境准备
- VMware 15.5por
- Centos7镜像文件
- Centos7下载链接
2.虚拟机Centos系统安装
https://blog.csdn.net/m0_51545690/article/details/123238360
3.静态网络配置
- 查看网络是否联通
- 安装net-tools
1
2
| yum upgrade
yum install net-tools
|
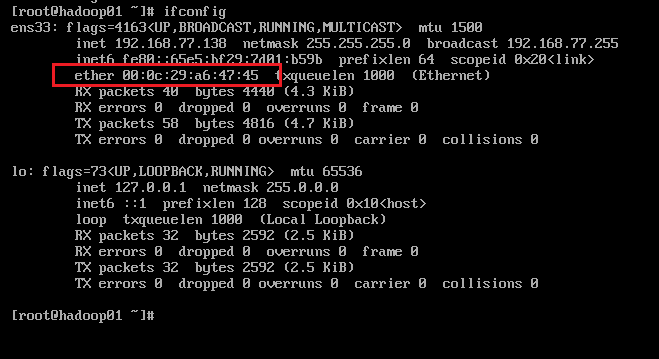
- 查看Mac地址
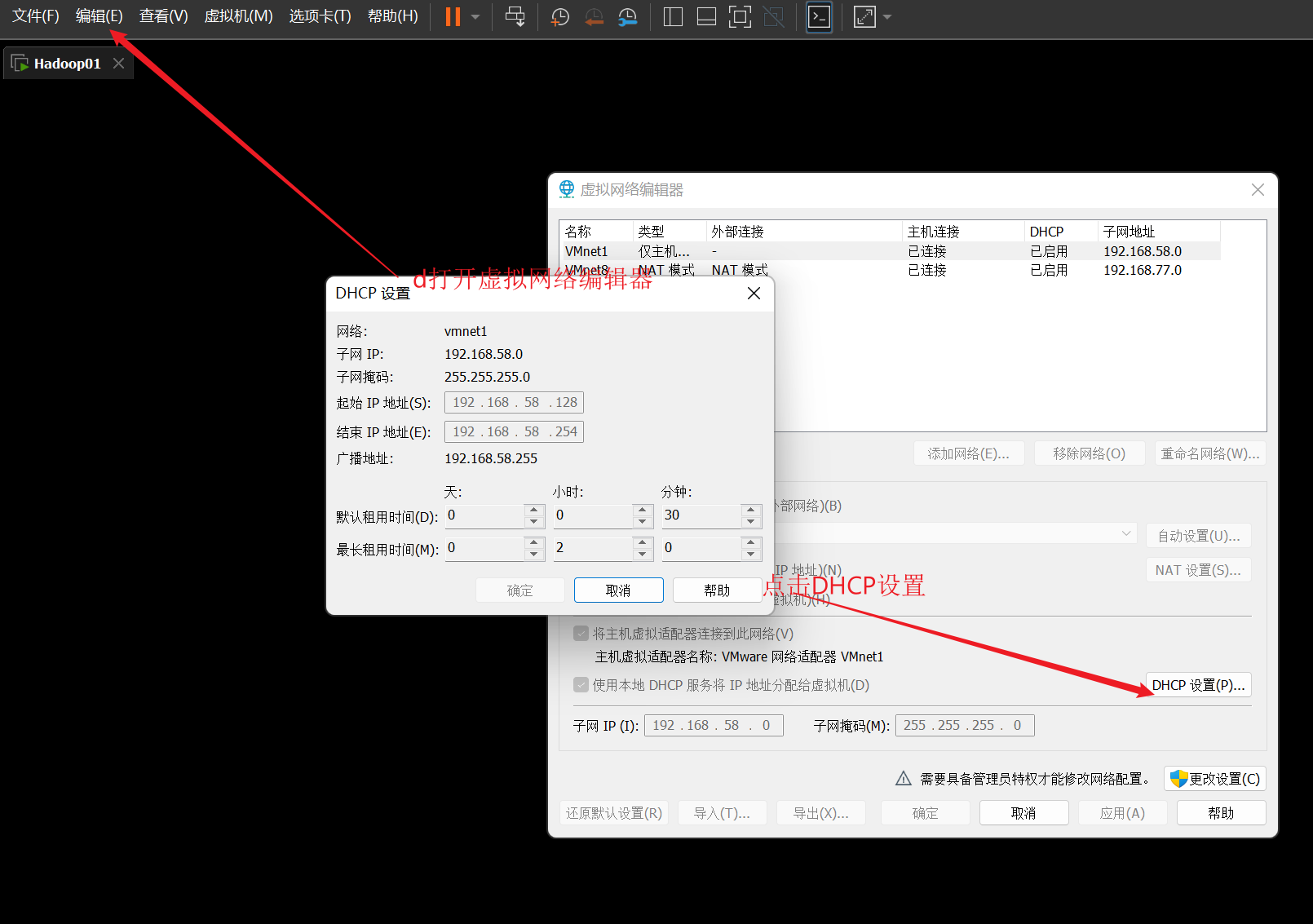
- 查看ip地址的起始和结束地址、
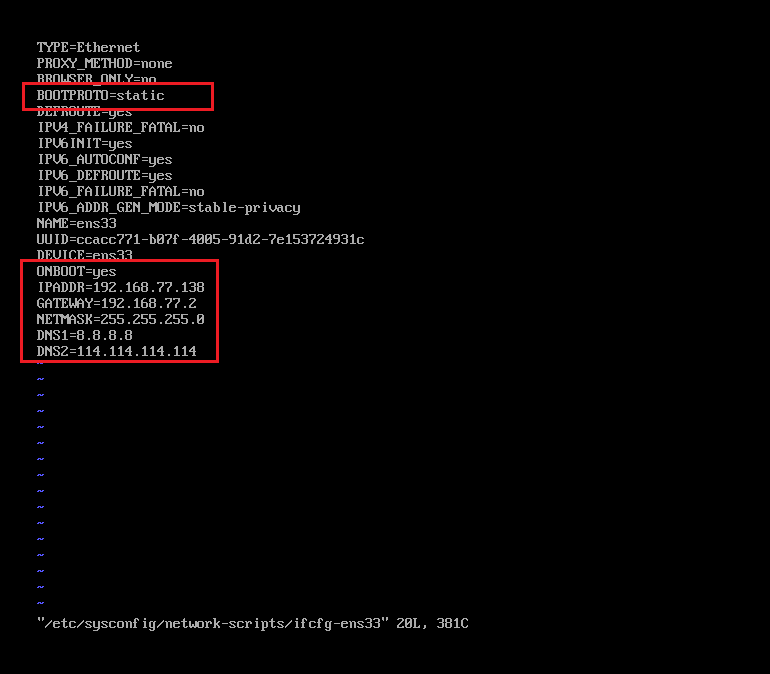
- 修改网络配置文件
1
| vi /etc/sysconfig/network-scripts/ifcfg-ens33
|
- 重启网络服务,查看是否配置成功

- 网络测试,输入以下命令
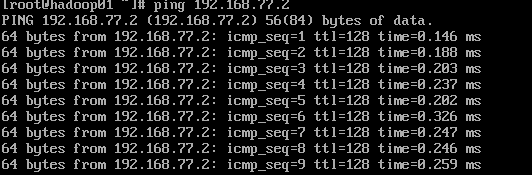
- 测试网络适配器:ping 192.168.77.2
- 测试网关:ping 192.168.77.2
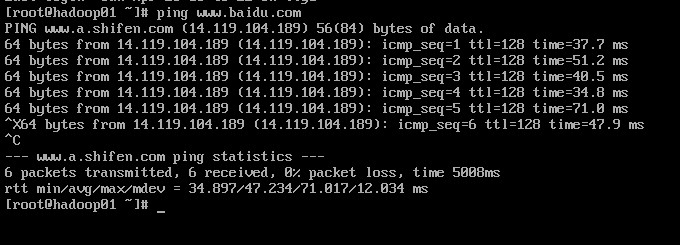
- 测试互联网:ping www.baidu.com
如图所示,说明网络是通的,否则说明网络参数有问题
2.虚拟机克隆配置
- 克隆虚拟机(右键相应虚拟机->管理->克隆)
- 开启Hadoop2,修改主机名
1
2
| hostnamectl set-hostname hadoop02
reboot
|

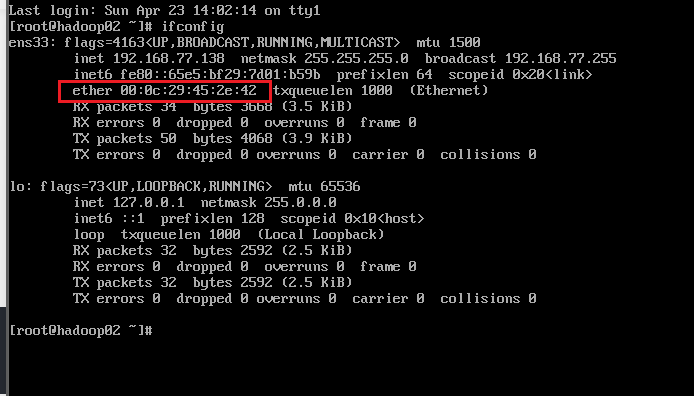
- 查看Mac地址
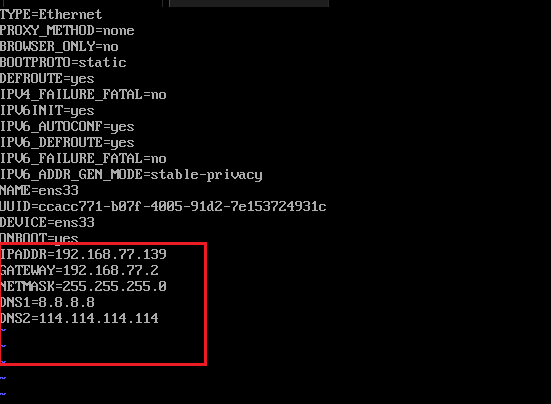
- 网络配置文件修改
1
| vi /etc/sysconfig/network-scripts/ifcfg-ens33
|
- 按照以上步骤在克隆另外一台虚拟机Hadoop03
3.配置hosts文件和ssh免密登录
- 修改hosts配置文件(所有虚拟机都需要配置)

- 生成密钥文件(四次回车)
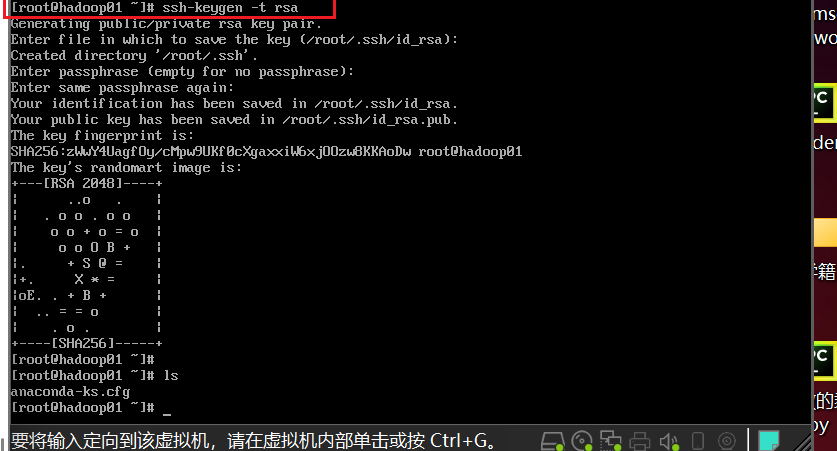
- 将本机公钥文件复制到其他虚拟机上(接收方需要开机)
在hadoop01上执行,先输入yes,后输入对应主机的密码,堕胎虚拟机配置操作相同
1
2
3
| ssh-copy-id hadoop01
ssh-copy-id hadoop02
ssh-copy-id hadoop03
|
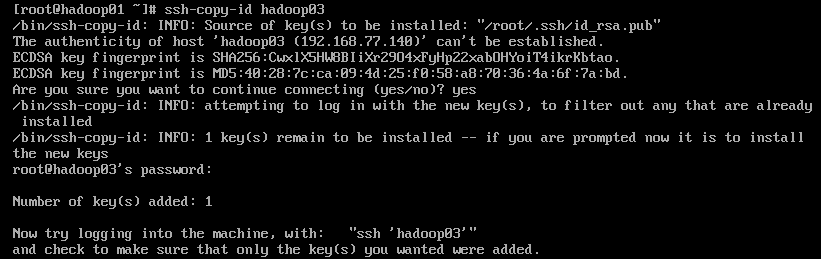
- 在虚拟机hadoop02,hadoop03都需要执行,保证三台主机都能免密登录
- 查看是否免密登录

4.Hadoop集群配置
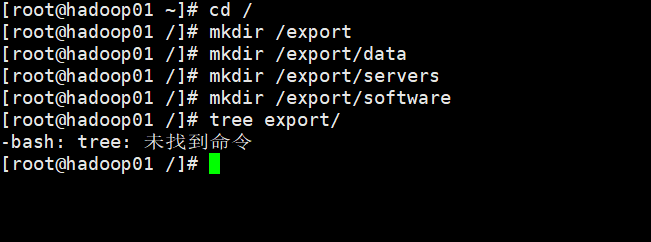
- 在所有虚拟机根目录下新建文件夹export,exportt文件夹中新建data、servers和software文件
1
2
3
4
5
| cd /
mkdir /export
mkdir /export/data
mkdir /export/servers
mkdir /export/software
|
准备安装包
hadoop-2.7.4.tar.gz
jdk-8u161-linux-x64.tar.gz
用Xshell依次连接hadoop1,2,3
- 先进入software文件内,然后把hadoop-2.7.4.tar.gz 、jdk-8u161-linux-x64.tar.gz上传进去
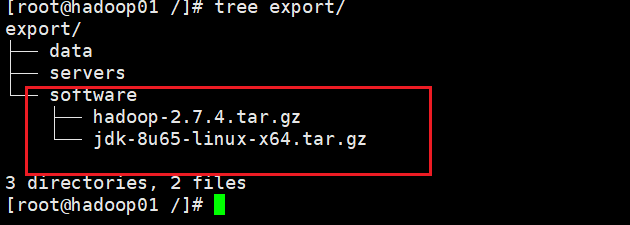
- 按照JDK(所有虚拟机都要操作)
- 解压jdk
1
2
| cd /export/software
tar -zxvf jdk-8u161-linux-x64.tar.gz -C /export/servers/
|
2. 重命名jdk目录
1
2
| cd /export/servers
mv jdk1.8.0_161 jdk
|
3. 配置环境变量
1
2
3
4
| #tip:在配置文件末尾追加
export JAVA_HOME=/export/servers/jdk
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
|

4. 使配置文件生效
5. 查看是否配置成功

- Hadoop安装(所有)
- 解压hadoop
1
2
| cd /export/software
tar -zxvf hadoop-2.7.4.tar.gz -C /export/servers/
|
2. 打开配置文件
3. 配置hadoop环境变量
1
2
3
| #tip:在文件末尾追加
export HADOOP_HOME=/export/servers/hadoop-2.7.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
|

4. 使配置文件生效
5. 查看是否配置成功
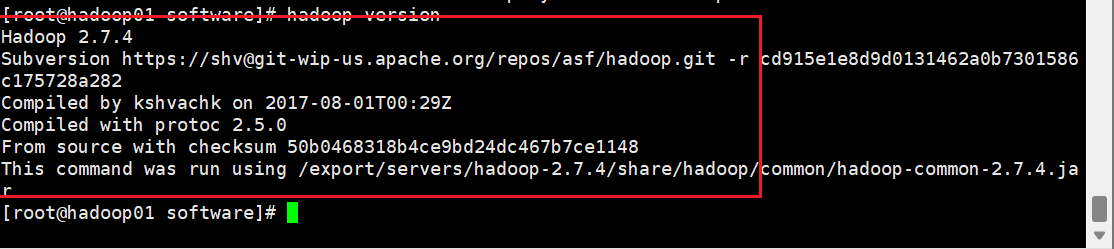
- Hadoop集群配置
- 进入主节点配置目录
1
| cd /export/servers/hadoop-2.7.4/etc/hadoop/
|
2. 修改hadoop-env.sh文件
1
2
3
| :wq:w
#tip:找到相应位置,添加这段话
export JAVA_HOME=/export/servers/jdk
|
3. 修改core-site.xml文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| <configuration>
<!
<property>
<name>fs.defaultFS</name>
<!
<value>hdfs://hadoop01:9000</value>
</property>
<!
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop-2.7.4/tmp</value>
</property>
</configuration>
|
4. 修改hdfs-site.xml文件
1
2
3
4
5
6
7
8
9
10
11
12
| <configuration>
<!
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop01:50090</value>
</property>
</configuration>
|
5. 修改mapred-site.xml文件
1
| cp mapred-site.xml.template mapred-site.xml
|
1
2
3
4
5
6
7
8
9
10
11
12
| <configuration>
<!
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
|
6. 修改yarn-site.xml文件
1
2
3
4
5
6
7
8
9
10
11
12
| <configuration>
<!
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
|
7. 修改slaves文件
1
2
3
| #tip:将文件中的localhost删除,添加主节点和子节点的主机名称
#tip:如主节点hadoop01,子节点hadoop02和hadoop03
vi slaves
|
8. 将主节点中配置号文件和hadoop目录coopy给予子节点
1
2
3
4
5
| #tip:这里主节点为hadoop01,子节点为hadoop02和hadoop03
scp /etc/profile hadoop02:/etc/profile
scp /etc/profile hadoop03:/etc/profile
scp -r /export/ hadoop02:/
scp -r /export/ hadoop03:/
|
9. 使子节点中的配置文件生效
1
2
| #tip:返回hadoop02和hadoop03节点执行下面命令
source /etc/profile
|
10. 使子节点格式化文件系统(successfully formatted格式化成功)
5.Hadoop集群测试
- 启动集群
- 在主节点启动所有HDFS服务进程
2. 在主节点启动所有HDFS服务进程
3. 使用jps命令查看进程
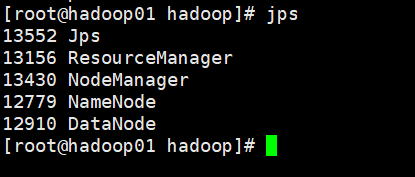
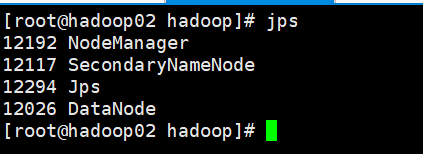
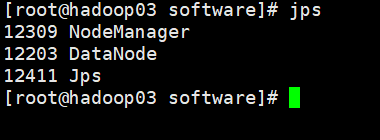
- 关闭防火墙
1
| systemctl stop firewalld #关闭防火墙
|
- 打开window下的C:\Windows\System32\drivers\etc打开hosts文件,在文件末添加三行代码:
192.168.77.138 hadoop01
192.168.77.139 hadoop02
192.168.77.140 hadoop03
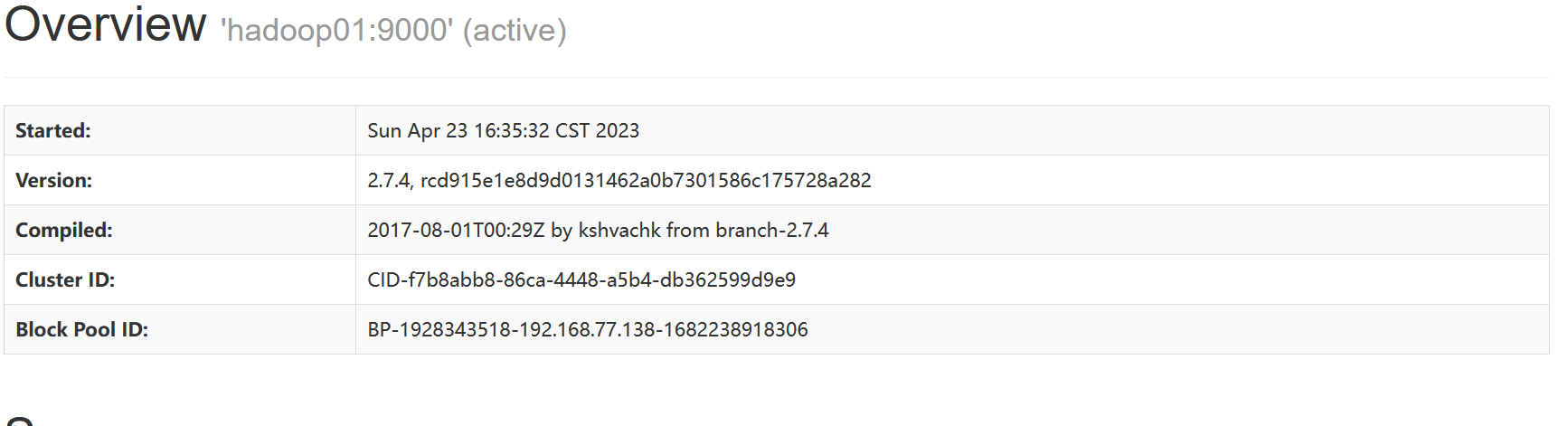
- 通过UI界面查看Hadoop运行状态,在windows系统下,访问http://hadoop01:50090,查看HDFS集群状态
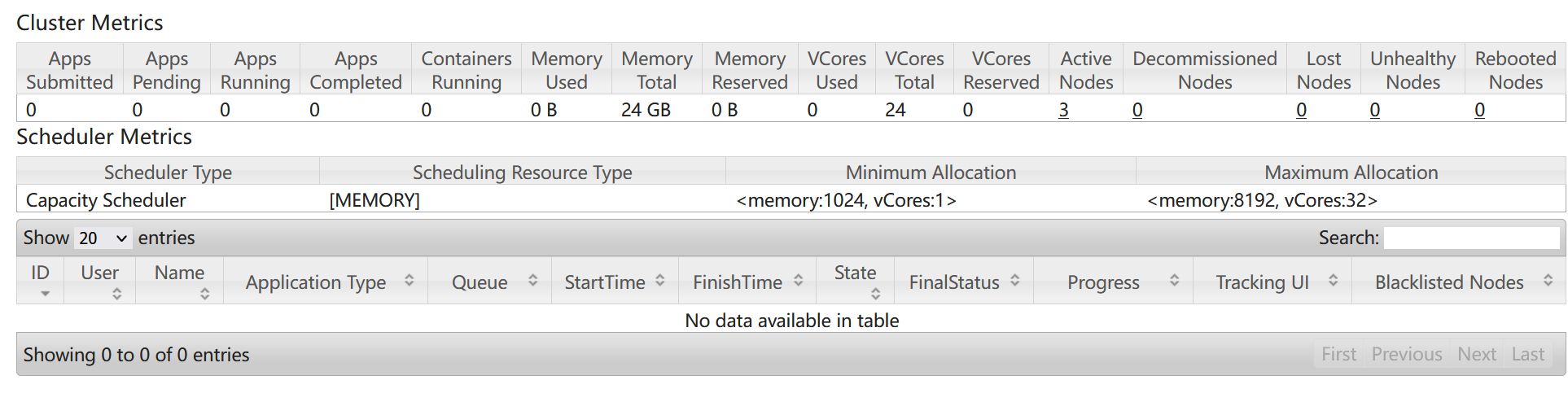
- 在windows下,访问http://hadoop01:8088,查看Yarn集群状态
hadoop核心hdfs命令使用
(1)在hdfs分布式文件系统上新建文件存储目录
1
| hdfs dfs -mkdir -p /user/hadoop
|

(2)上传本地文件到hdfs分布式文件系统的指定目录中
1
| hdfs dfs -put test.txt /user/hadoop/
|

(3)查看hdfs分布式文件系统内容
1
| hdfs dfs -ls /user/hadoop
|

(4)查看上传文件信息
1
| hdfs dfs -cat /user/hadoop/test.txt
|

(5) 下载hdfs分布式文件系统上文件到本地目录
1
| hdfs dfs -get /user/hadoop/test.txt
|
 jps
jps
(6)删除hdfs分布式文件系统内容
1
| hdfs dfs -rm /user/hadoop/test.txt
|


(7)运行一个简易的MapReduce程序
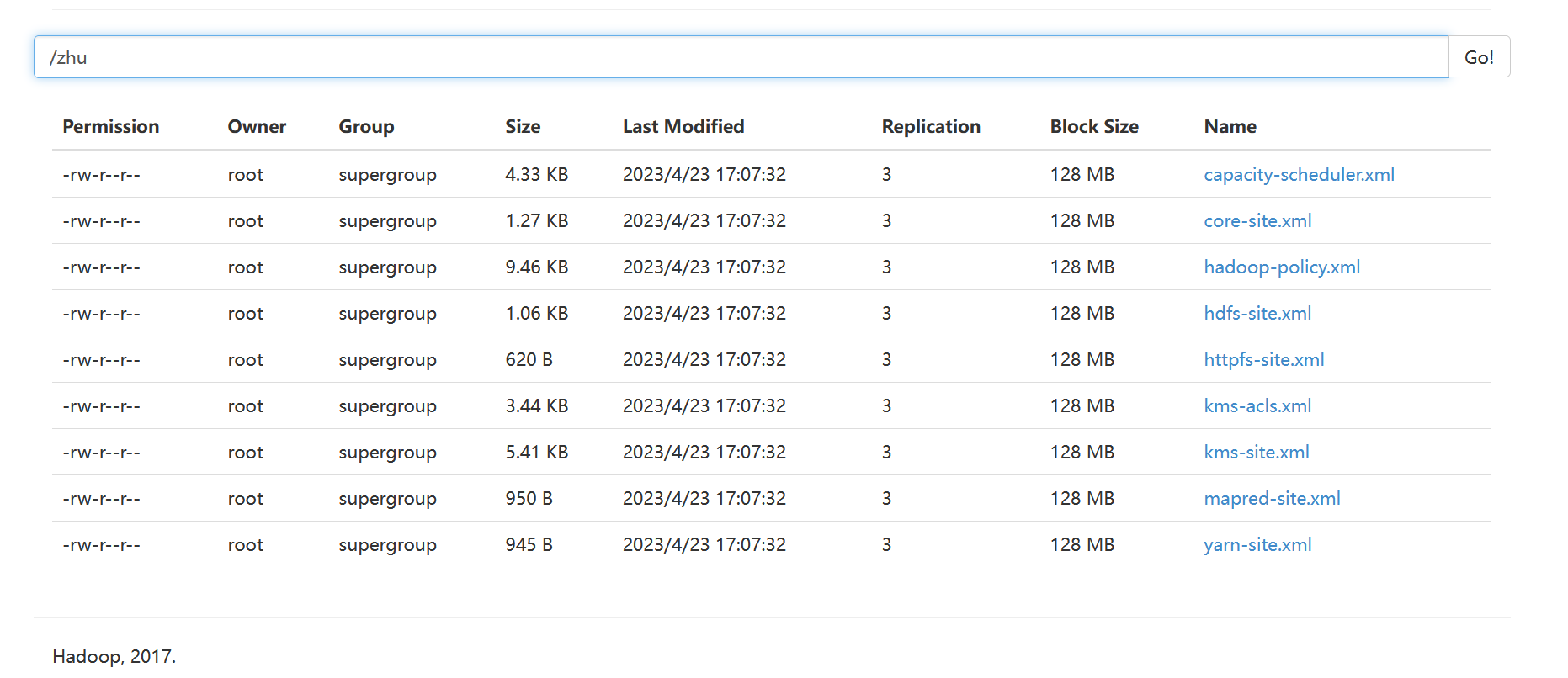
第一步先从本地上传进行统计计算的文件到hdfs文件系统中。例如将/export/servers/hadoop-2.7.4/etc/hadoop中的*.xml配置文件上传到hdfs的/zhu目录下,如图所示。
1
2
| [root@hadoop01 ~]# hdfs dfs -mkdir -p /zhu
[root@hadoop01 ~]# hdfs dfs -put /export/servers/hadoop-2.7.4/etc/hadoop
|
第二步使用hadoop提供的一个jar包,按照正则表达式进行统计。命令如下:
1
| jar /export/servers/hadoop-2.7.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar grep /zhu /optput 'dfs[a-z]+'
|
结果:

启动/关闭
启动之前必须进行一次格式化操作
1
| bin/hadoop namenode -format
|
启动hadoop:sbin/start-dfs.sh
关闭hadoop:sbin/stop-dfs.sh
启动yarn:sbin/start-yarn.sh
关闭yarn:sbin/stop-yarn.sh