介绍
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎,是类似于Hadoop MapReduce的通用并行框架。Spark拥有Hadoop MapReduce所具有的优点,但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。Spark实际上是对Hadoop的一种补充,可以很好的在Hadoop 文件系统中并行运行。
环境配置
解压 、配置
1 | # 解压 |
修改 spark-env.sh文件
1 | [root@master spark]# cd spark-2.4.0/conf/ |
修改slaves文件
1 | [root@master conf]# mv slaves.template slaves |
在其余两个子节点上操作
1 | [root@master servers]# scp -r /app/servers/spark-2.4.0/ slave1:/app/servers/ |
启动
1 | [root@master local]# cd spark/spark-2.4.0/ |
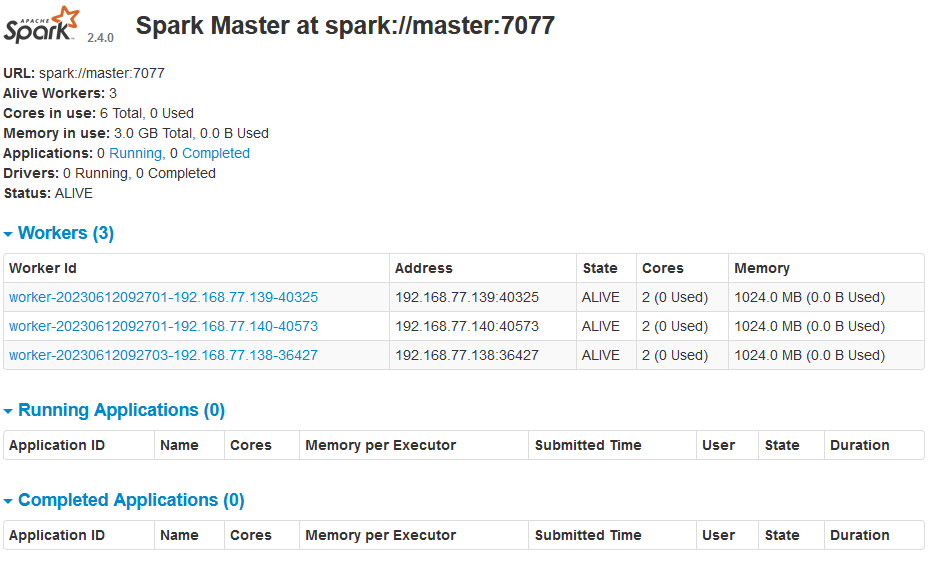
启动完毕后在主机浏览器访问界面:http://192.168.77.138:8080/